Doing more with spatial data
Installation
Yopu may need to install ioos and geopandas to run this notebook:
conda install -c ioos geopandas=0.2.0.dev0
Using SD to understand the SD Fever
A new emerging infectious disease in Europe, which does not spread to neighboring countries
In this script, we will use georeferenced data at a national level to simulate a multiregional infectious disease model. We’ll then present the advantages to project spatial data produced by our simulation back on a map.
%matplotlib inline
import pandas as pd
import pysd
A simple SIR model
The model we’ll use to represent the dynamics of the disease is a simple SIR model, with individuals aggregated into stocks by their health condition S-Susceptible, I-Infectious, R-Recovered. We assume that the complete population is susceptible, therefore the initial value of susceptible stock is equal to the total population. In addition, we built on the hypothesis that from now all infected person are reported.
from IPython.display import Image
Image(filename='../../models/SD_Fever/SIR_model.png')
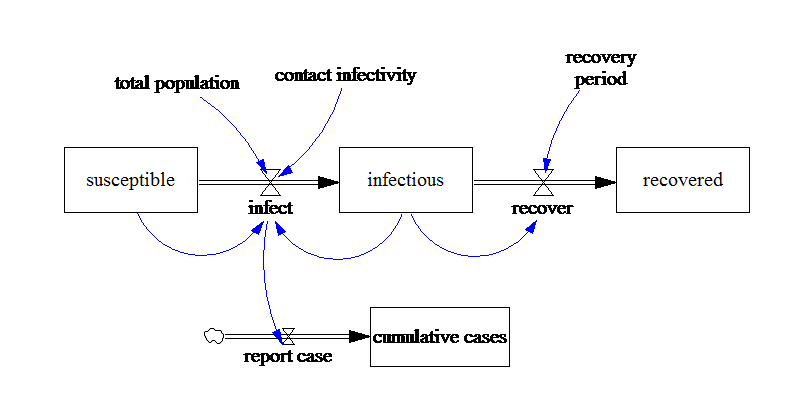
In Vensim our model was parameterized with 1000 suceptible, 5 infectious and 0 recovered individuals, a recovery period of 5 days and a contact infectivity of 70%.
When we do not specificy anything else, the parameters and setting (e.g. timestep, simulation time) from the Vensim model are used.
model = pysd.read_vensim('../../models/SD_Fever/SIR_Simple.mdl')
result = model.run(return_columns=[
'cumulative cases', 'report case', 'infect',
'contact infectivity', 'recovery period', 'infectious',
'recovered', 'recover', 'susceptible', 'total population'
])
result.plot();
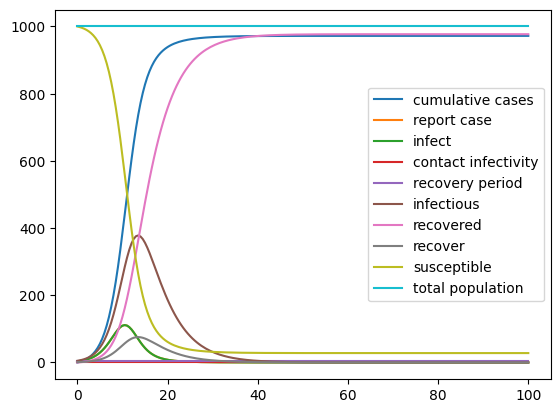
Recap
Modify parameter values
As we have seen before, we can specify changes to the parameters of the model in the call to the run function. Here we set the contact infectivity to 30% before running the simulation again. If you like, try what happens when you change some of the other parameters.
result = model.run(params={ 'total_population':1000,
'contact_infectivity':.3,
'recovery_period': 5
},
return_columns=[
'cumulative cases', 'report case', 'infect',
'contact infectivity', 'recovery period', 'infectious',
'recovered', 'recover', 'susceptible', 'total population']
)
result.plot();
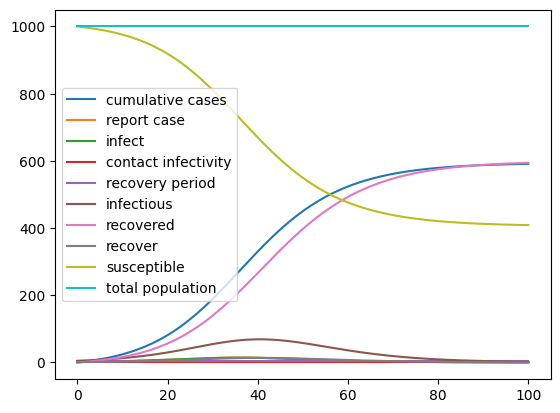
Change Model settings
We can also change in a very simpe manner the simulation time and timestep of the model. An easy way to do it is to use numpy linspace which returns evenly spaced numbers over a specified interval.
np.linspace(Start, Stop, Number of timestamps)
import numpy as np
sim_time = 10
np.linspace(0, sim_time, num=sim_time*4+1)
array([ 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ,
2.25, 2.5 , 2.75, 3. , 3.25, 3.5 , 3.75, 4. , 4.25,
4.5 , 4.75, 5. , 5.25, 5.5 , 5.75, 6. , 6.25, 6.5 ,
6.75, 7. , 7.25, 7.5 , 7.75, 8. , 8.25, 8.5 , 8.75,
9. , 9.25, 9.5 , 9.75, 10. ])
We can use the return_timestamps keyword argument in PySD. This argument expects a list of timestamps, and will return simulation results at those timestamps.
model.run(return_timestamps=np.linspace(0, sim_time, num=sim_time*2+1))
| FINAL TIME | INITIAL TIME | SAVEPER | TIME STEP | cumulative cases | report case | infect | contact infectivity | recovery period | infectious | recovered | recover | susceptible | total population | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 10.0 | 0 | 0.5 | 0.5 | 0.000000 | 1.500000 | 1.500000 | 0.3 | 5 | 5.000000 | 0.000000 | 1.000000 | 1000.000000 | 1000 |
| 0.5 | 10.0 | 0 | 0.5 | 0.5 | 0.750000 | 1.573819 | 1.573819 | 0.3 | 5 | 5.250000 | 0.500000 | 1.050000 | 999.250000 | 1000 |
| 1.0 | 10.0 | 0 | 0.5 | 0.5 | 1.536909 | 1.651031 | 1.651031 | 0.3 | 5 | 5.511909 | 1.025000 | 1.102382 | 998.463091 | 1000 |
| 1.5 | 10.0 | 0 | 0.5 | 0.5 | 2.362425 | 1.731769 | 1.731769 | 0.3 | 5 | 5.786234 | 1.576191 | 1.157247 | 997.637575 | 1000 |
| 2.0 | 10.0 | 0 | 0.5 | 0.5 | 3.228310 | 1.816166 | 1.816166 | 0.3 | 5 | 6.073495 | 2.154814 | 1.214699 | 996.771690 | 1000 |
| 2.5 | 10.0 | 0 | 0.5 | 0.5 | 4.136393 | 1.904359 | 1.904359 | 0.3 | 5 | 6.374229 | 2.762164 | 1.274846 | 995.863607 | 1000 |
| 3.0 | 10.0 | 0 | 0.5 | 0.5 | 5.088572 | 1.996484 | 1.996484 | 0.3 | 5 | 6.688986 | 3.399587 | 1.337797 | 994.911428 | 1000 |
| 3.5 | 10.0 | 0 | 0.5 | 0.5 | 6.086815 | 2.092683 | 2.092683 | 0.3 | 5 | 7.018329 | 4.068485 | 1.403666 | 993.913185 | 1000 |
| 4.0 | 10.0 | 0 | 0.5 | 0.5 | 7.133156 | 2.193095 | 2.193095 | 0.3 | 5 | 7.362838 | 4.770318 | 1.472568 | 992.866844 | 1000 |
| 4.5 | 10.0 | 0 | 0.5 | 0.5 | 8.229704 | 2.297863 | 2.297863 | 0.3 | 5 | 7.723102 | 5.506602 | 1.544620 | 991.770296 | 1000 |
| 5.0 | 10.0 | 0 | 0.5 | 0.5 | 9.378635 | 2.407128 | 2.407128 | 0.3 | 5 | 8.099723 | 6.278912 | 1.619945 | 990.621365 | 1000 |
| 5.5 | 10.0 | 0 | 0.5 | 0.5 | 10.582199 | 2.521031 | 2.521031 | 0.3 | 5 | 8.493314 | 7.088885 | 1.698663 | 989.417801 | 1000 |
| 6.0 | 10.0 | 0 | 0.5 | 0.5 | 11.842715 | 2.639714 | 2.639714 | 0.3 | 5 | 8.904499 | 7.938216 | 1.780900 | 988.157285 | 1000 |
| 6.5 | 10.0 | 0 | 0.5 | 0.5 | 13.162571 | 2.763314 | 2.763314 | 0.3 | 5 | 9.333905 | 8.828666 | 1.866781 | 986.837429 | 1000 |
| 7.0 | 10.0 | 0 | 0.5 | 0.5 | 14.544228 | 2.891969 | 2.891969 | 0.3 | 5 | 9.782172 | 9.762056 | 1.956434 | 985.455772 | 1000 |
| 7.5 | 10.0 | 0 | 0.5 | 0.5 | 15.990213 | 3.025812 | 3.025812 | 0.3 | 5 | 10.249939 | 10.740274 | 2.049988 | 984.009787 | 1000 |
| 8.0 | 10.0 | 0 | 0.5 | 0.5 | 17.503119 | 3.164972 | 3.164972 | 0.3 | 5 | 10.737852 | 11.765268 | 2.147570 | 982.496881 | 1000 |
| 8.5 | 10.0 | 0 | 0.5 | 0.5 | 19.085605 | 3.309572 | 3.309572 | 0.3 | 5 | 11.246552 | 12.839053 | 2.249310 | 980.914395 | 1000 |
| 9.0 | 10.0 | 0 | 0.5 | 0.5 | 20.740391 | 3.459729 | 3.459729 | 0.3 | 5 | 11.776683 | 13.963708 | 2.355337 | 979.259609 | 1000 |
| 9.5 | 10.0 | 0 | 0.5 | 0.5 | 22.470255 | 3.615554 | 3.615554 | 0.3 | 5 | 12.328879 | 15.141376 | 2.465776 | 977.529745 | 1000 |
| 10.0 | 10.0 | 0 | 0.5 | 0.5 | 24.278032 | 3.777147 | 3.777147 | 0.3 | 5 | 12.903768 | 16.374264 | 2.580754 | 975.721968 | 1000 |
Multi-regional SIR Model
Geographical Information
Geospatial information as area on a map linked to several properties are typically stored into shapefiles.
For this script, we will use geopandas library to manage the shapefiles, and utilize its inherent plotting functionality.
import geopandas as gp
shapefile = '../../data/SD_Fever/geo_df_EU.shp'
geo_data = gp.GeoDataFrame.from_file(shapefile)
geo_data.head(5)
| population | country | inf_rate | geometry | |
|---|---|---|---|---|
| 0 | 5347896.0 | Norway | 0.012681 | MULTIPOLYGON (((15.14282 79.67431, 15.52255 80... |
| 1 | 67059887.0 | France | 0.276615 | MULTIPOLYGON (((-51.65780 4.15623, -52.24934 3... |
| 2 | 10285453.0 | Sweden | 0.034167 | POLYGON ((11.02737 58.85615, 11.46827 59.43239... |
| 3 | 9466856.0 | Belarus | 0.096774 | POLYGON ((28.17671 56.16913, 29.22951 55.91834... |
| 4 | 44385155.0 | Ukraine | 0.186621 | POLYGON ((31.78599 52.10168, 32.15944 52.06125... |
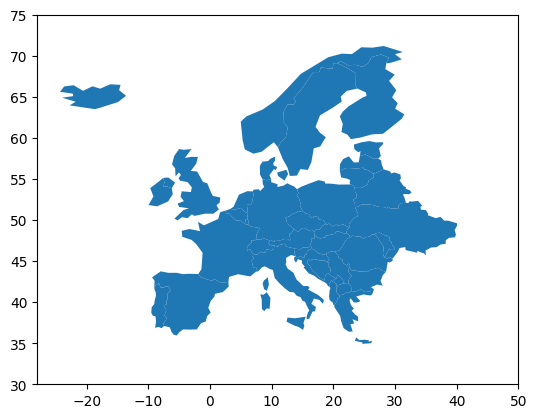
Then we can project the geographic shape of the elements on a map.
import matplotlib.pyplot as plt
geo_data.plot()
plt.xlim([-28, 50])
plt.ylim([30, 75])
plt.show()
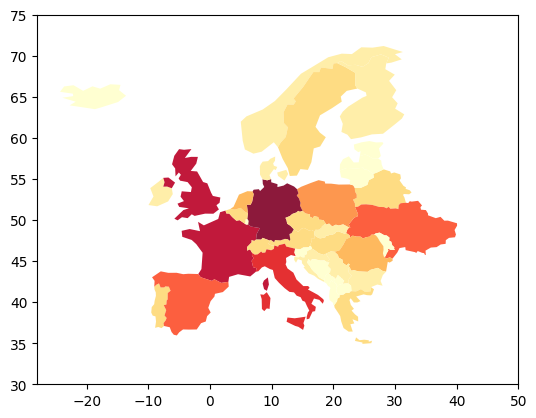
And plot on of the georeferenced property (e.g. population)
geo_data.plot(column='population', scheme='fisher_jenks', alpha=0.9, k=9, linewidth=0.1,
cmap=plt.cm.YlOrRd, legend=False)
plt.xlim([-28, 50])
plt.ylim([30, 75])
plt.show()
Run the model for each country
We want to run the core SD model for each country, with country specific paramterization.
Thus, we formulate a function that based on each row parameterizes the model with the value from geodata, performs the simulation and finally returns the number of infectious individuals over time.
def runner(row):
sim_time = 200
params= {'total_population': row['population'],
'contact_infectivity' : row['inf_rate']}
res = model.run(params=params,
return_timestamps=np.linspace(0, sim_time, num=sim_time*2+1))
return res['infectious']
Apply function along rows of the Dataframe.
We want to apply the function row-wise (by country) therefore we set axis to 1 (row) instead of default 0 (column). The result is a new dataframe with the produced simulation for each country.
res = geo_data.apply(runner, axis=1)
res.head()
| 0.0 | 0.5 | 1.0 | 1.5 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 | 4.5 | ... | 195.5 | 196.0 | 196.5 | 197.0 | 197.5 | 198.0 | 198.5 | 199.0 | 199.5 | 200.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.0 | 4.531702 | 4.107264 | 3.722579 | 3.373923 | 3.057923 | 2.771519 | 2.511939 | 2.276672 | 2.063439 | ... | 9.996953e-17 | 9.060642e-17 | 8.212025e-17 | 7.442889e-17 | 6.745791e-17 | 6.113982e-17 | 5.541348e-17 | 5.022347e-17 | 4.551956e-17 | 4.125621e-17 |
| 1 | 5.0 | 5.191538 | 5.390414 | 5.596907 | 5.811312 | 6.033929 | 6.265074 | 6.505074 | 6.754268 | 7.013008 | ... | 2.877902e+06 | 2.880190e+06 | 2.880756e+06 | 2.879608e+06 | 2.876757e+06 | 2.872216e+06 | 2.866006e+06 | 2.858148e+06 | 2.848668e+06 | 2.837596e+06 |
| 2 | 5.0 | 4.585418 | 4.205211 | 3.856530 | 3.536761 | 3.243505 | 2.974565 | 2.727925 | 2.501735 | 2.294300 | ... | 1.001973e-14 | 9.188925e-15 | 8.427012e-15 | 7.728275e-15 | 7.087474e-15 | 6.499806e-15 | 5.960865e-15 | 5.466611e-15 | 5.013340e-15 | 4.597651e-15 |
| 3 | 5.0 | 4.741935 | 4.497189 | 4.265076 | 4.044943 | 3.836171 | 3.638175 | 3.450397 | 3.272312 | 3.103418 | ... | 5.015702e-09 | 4.756826e-09 | 4.511312e-09 | 4.278469e-09 | 4.057645e-09 | 3.848217e-09 | 3.649599e-09 | 3.461232e-09 | 3.282588e-09 | 3.113163e-09 |
| 4 | 5.0 | 4.966553 | 4.933330 | 4.900329 | 4.867548 | 4.834987 | 4.802644 | 4.770517 | 4.738605 | 4.706907 | ... | 3.624228e-01 | 3.599984e-01 | 3.575902e-01 | 3.551980e-01 | 3.528219e-01 | 3.504617e-01 | 3.481173e-01 | 3.457885e-01 | 3.434754e-01 | 3.411777e-01 |
5 rows × 401 columns
Transpose simulation results for plotting
The pandas line plot assumes that rows represent the timeseries and columns the different objects. Since our data is not yet in this form, we have to transpose the data. In pandas all we have to do is add an .T at the end.
import pandas as pd
df = pd.DataFrame(res).T
df.head(2)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.00000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | ... | 5.0 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 |
| 0.5 | 4.531702 | 5.191538 | 4.585418 | 4.741935 | 4.966553 | 5.19772 | 5.152267 | 5.165813 | 5.015223 | 5.021537 | ... | 4.5 | 5.202822 | 4.552659 | 5.210224 | 5.290059 | 4.928924 | 5.074109 | 5.102701 | 4.807623 | 5.598635 |
2 rows × 38 columns
df.plot(legend=False);
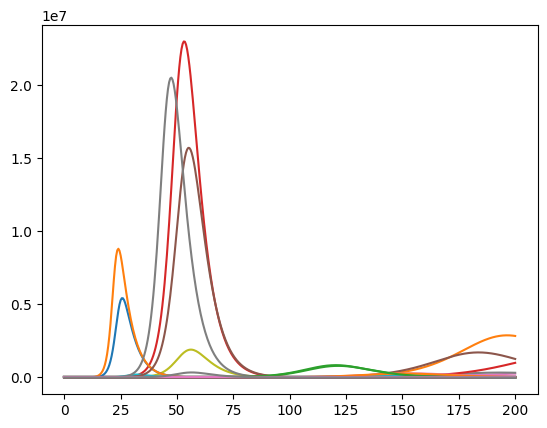
Comparative Analysis
Next lets try to compare how severe a country is hit by the SD fever.
Rather than looking at the number of infectious persons over time, a better indicator for comparative analysis are the cumulative cases as percentage of population in each country.
We can reuse our code from before but instead of returning the number of infecious we return the cumulative cases.
def runner(row):
sim_time = 200
params= {'total_population':row['population'],
'contact_infectivity' : row['inf_rate']}
res = model.run(params=params,
return_timestamps=range(0,sim_time))
return res['cumulative cases']
#TIP: Ensure you are using lower case letters and the character _ not space
res = geo_data.apply(runner, axis=1)
res.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.060434 | 0.110078 | 0.150858 | 0.184356 | 0.211874 | 0.234479 | 0.253047 | 0.268300 | 0.280830 | ... | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 | 3.384762e-01 |
| 1 | 0.0 | 1.409567 | 2.929197 | 4.567484 | 6.333693 | 8.237812 | 10.290610 | 12.503695 | 14.889584 | 17.461770 | ... | 1.494990e+07 | 1.553967e+07 | 1.613077e+07 | 1.672170e+07 | 1.731093e+07 | 1.789700e+07 | 1.847848e+07 | 1.905399e+07 | 1.962224e+07 | 2.018199e+07 |
| 2 | 0.0 | 0.163753 | 0.301477 | 0.417308 | 0.514727 | 0.596660 | 0.665570 | 0.723525 | 0.772269 | 0.813264 | ... | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 | 1.030168e+00 |
| 3 | 0.0 | 0.471383 | 0.895363 | 1.276706 | 1.619701 | 1.928203 | 2.205682 | 2.455257 | 2.679734 | 2.881637 | ... | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 | 4.687479e+00 |
| 4 | 0.0 | 0.929985 | 1.847569 | 2.752919 | 3.646196 | 4.527562 | 5.397177 | 6.255195 | 7.101773 | 7.937062 | ... | 6.430156e+01 | 6.437414e+01 | 6.444574e+01 | 6.451640e+01 | 6.458611e+01 | 6.465489e+01 | 6.472275e+01 | 6.478971e+01 | 6.485577e+01 | 6.492096e+01 |
5 rows × 200 columns
Now, how do we get from the cumulative cases to the cumulative cases as % of the population?
The answer is a simple matrix operation: divide row-wise the elements of our computed values by the column of the original geo data set where we had the population in each country.
Let’s try to perform this type of operation on a minimal example.
# Create arbitrary column
column = pd.Series([10, 2])
column
0 10
1 2
dtype: int64
# Create arbitrary pandas dataframe
df = pd.DataFrame(np.random.randint(1,5,size=(2, 3)), columns=list('ABC'))
df
| A | B | C | |
|---|---|---|---|
| 0 | 3 | 3 | 3 |
| 1 | 4 | 4 | 2 |
column*df["A"]
0 30
1 8
dtype: int64
Now we can translate this operation on our actual problem.
res = pd.DataFrame(res.T/geo_data["population"])
res.plot(legend=False);
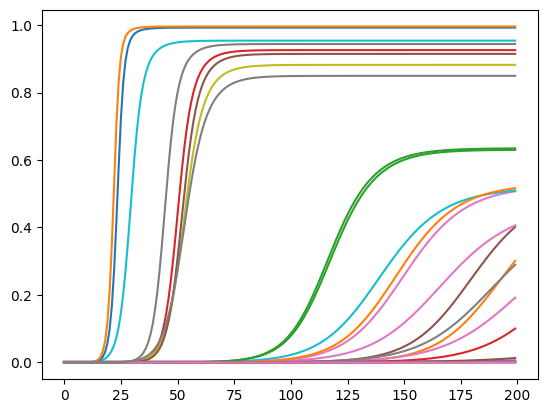
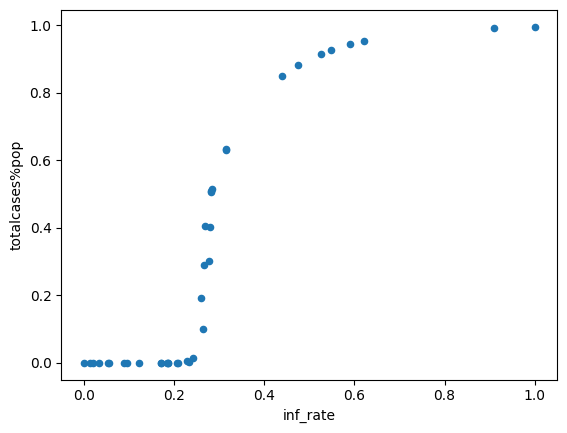
Analysis of results
For example, we could study the impact of contact infectivity on the cumulative cases at the end of the simulation
geo_data['totalcases%pop'] = res.loc[199] # Slice the final value at the end of the simulation
df_scatter = pd.DataFrame(geo_data) # Geopandas dataframe to pandas Dataframe (geopandas tries to perform spatial analysis)
df_scatter.plot.scatter(x='inf_rate', y='totalcases%pop'); # Plot infectivity versus cumulative cases at the end of the simulation
How Spatial Analysis Leads to Insight
Finally, we present slighltly advanced Python scripts to get our simulation results projected on the map.
We merge the complete simulation results with our original georeferenced information just as we did in the step before.
geo_data.head(2)
| population | country | inf_rate | geometry | totalcases%pop | |
|---|---|---|---|---|---|
| 0 | 5347896.0 | Norway | 0.012681 | MULTIPOLYGON (((15.14282 79.67431, 15.52255 80... | 6.329147e-08 |
| 1 | 67059887.0 | France | 0.276615 | MULTIPOLYGON (((-51.65780 4.15623, -52.24934 3... | 3.009547e-01 |
res.head(2)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | ... | 0.0 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000e+00 | 0.000000 |
| 1 | 1.130052e-08 | 2.101953e-08 | 1.592086e-08 | 4.979298e-08 | 2.095261e-08 | 3.747692e-08 | 1.491931e-07 | 1.385581e-07 | 3.883204e-07 | 5.400350e-08 | ... | 0.0 | 6.868723e-07 | 1.822466e-08 | 2.659132e-07 | 1.523894e-07 | 2.580278e-07 | 5.551959e-07 | 1.753471e-07 | 9.698978e-07 | 0.000001 |
2 rows × 38 columns
geo_data_merged = geo_data.merge(res.T, left_index=True, right_index=True)
geo_data_merged.head()
| population | country | inf_rate | geometry | totalcases%pop | 0 | 1 | 2 | 3 | 4 | ... | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5347896.0 | Norway | 0.012681 | MULTIPOLYGON (((15.14282 79.67431, 15.52255 80... | 6.329147e-08 | 0.0 | 1.130052e-08 | 2.058336e-08 | 2.820878e-08 | 3.447269e-08 | ... | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 | 6.329147e-08 |
| 1 | 67059887.0 | France | 0.276615 | MULTIPOLYGON (((-51.65780 4.15623, -52.24934 3... | 3.009547e-01 | 0.0 | 2.101953e-08 | 4.368032e-08 | 6.811053e-08 | 9.444831e-08 | ... | 2.229336e-01 | 2.317283e-01 | 2.405428e-01 | 2.493547e-01 | 2.581413e-01 | 2.668809e-01 | 2.755519e-01 | 2.841340e-01 | 2.926077e-01 | 3.009547e-01 |
| 2 | 10285453.0 | Sweden | 0.034167 | POLYGON ((11.02737 58.85615, 11.46827 59.43239... | 1.001578e-07 | 0.0 | 1.592086e-08 | 2.931097e-08 | 4.057262e-08 | 5.004414e-08 | ... | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 | 1.001578e-07 |
| 3 | 9466856.0 | Belarus | 0.096774 | POLYGON ((28.17671 56.16913, 29.22951 55.91834... | 4.951463e-07 | 0.0 | 4.979298e-08 | 9.457867e-08 | 1.348606e-07 | 1.710917e-07 | ... | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 | 4.951463e-07 |
| 4 | 44385155.0 | Ukraine | 0.186621 | POLYGON ((31.78599 52.10168, 32.15944 52.06125... | 1.462673e-06 | 0.0 | 2.095261e-08 | 4.162584e-08 | 6.202341e-08 | 8.214900e-08 | ... | 1.448718e-06 | 1.450353e-06 | 1.451966e-06 | 1.453558e-06 | 1.455129e-06 | 1.456678e-06 | 1.458207e-06 | 1.459716e-06 | 1.461204e-06 | 1.462673e-06 |
5 rows × 205 columns
Plotting simulation results on map with Ipywidgets
Ipywidgets are interactive HTML widgets for IPython notebooks. Users gain control of their data and can visualize changes in the data.
import matplotlib as mpl
from ipywidgets import interact, FloatSlider, IntSlider,RadioButtons, Dropdown
sim_time = 200
slider_time = IntSlider(description = 'Time Select',
min=0, max=sim_time-1, value=1)
@interact(time = slider_time) # Scenario = select_scenario,
def update_map(time): # Scenario
ax = geo_data_merged.plot(column=time, scheme='fisherjenks', alpha=0.9, k=9, linewidth=0.1,
cmap=plt.cm.Reds, legend=True, figsize=(20, 30))
plt.xlim(-28, 50)
plt.ylim(30, 75)
plt.xticks([])
plt.yticks([])
interactive(children=(IntSlider(value=1, description='Time Select', max=199), Output()), _dom_classes=('widget…