Surrogating a function with a machine learning estimator
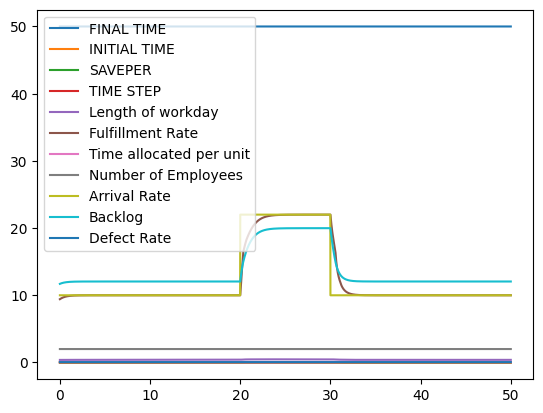
System dynamics generally represents the relationships between model elements as either analytical equations, or lookup tables. However, in some situations we may be presented with relationships that are not well estimated by equations, but involve more than a single input leading to a single output. When confrontied with this situation, other paradigms
%pylab inline
import pysd
import numpy as np
import pandas as pd
Populating the interactive namespace from numpy and matplotlib
model = pysd.read_vensim('../../models/Manufacturing_Defects/Defects.mdl')
data = pd.read_csv('../../data/Defects_Synthetic/Manufacturing_Defects_Synthetic_Data.csv')
data.head()
| Unnamed: 0 | Workday | Time per Task | Defect Rate | |
|---|---|---|---|---|
| 0 | 0 | 0.303114 | 0.060810 | 0.023022 |
| 1 | 1 | 0.263133 | 0.052325 | 0.023017 |
| 2 | 2 | 0.230397 | 0.065387 | 0.015868 |
| 3 | 3 | 0.265632 | 0.044866 | 0.032806 |
| 4 | 4 | 0.298651 | 0.038648 | 0.035234 |
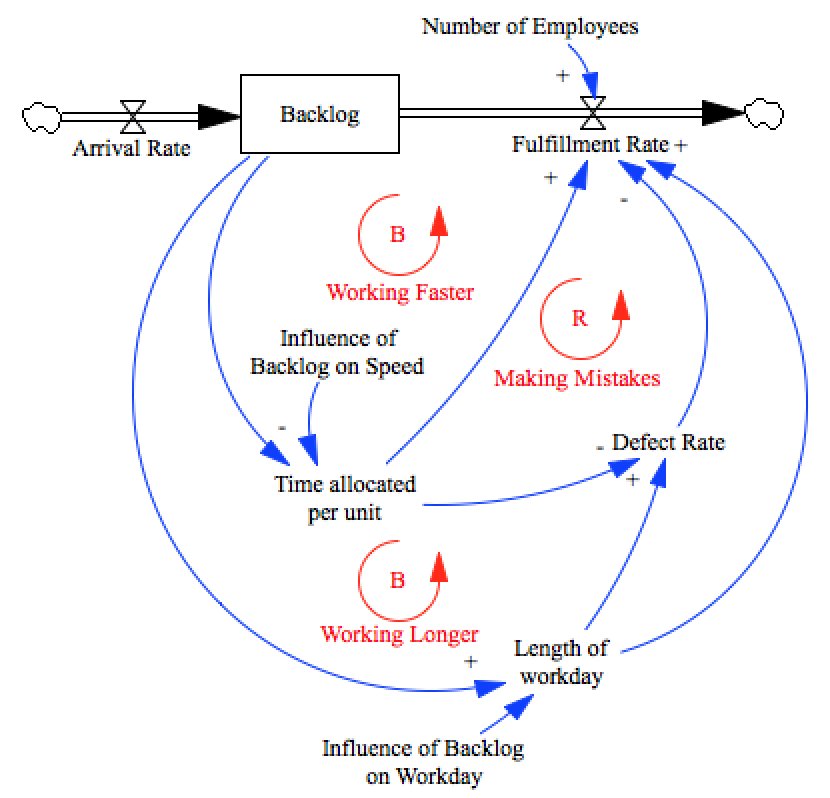
plt.scatter(data['Workday'], data['Time per Task'], c=data['Defect Rate'], linewidth=0, alpha=.6)
plt.ylabel('Time per Task')
plt.xlabel('Length of Workday')
plt.xlim(0.15, .45)
plt.ylim(.01, .09)
plt.box('off')
plt.colorbar()
plt.title('Defect Rate Measurements')
plt.figtext(.88, .5, 'Defect Rate', rotation=90, verticalalignment='center');
from sklearn.svm import SVR
Factors = data[['Workday','Time per Task']].values
Outcome = data['Defect Rate'].values
regression = SVR()
regression.fit(Factors, Outcome)
SVR()
def new_defect_function():
""" Replaces the original defects equation with a regression model"""
workday = model.components.length_of_workday()
time_per_task = model.components.time_allocated_per_unit()
return regression.predict([[workday, time_per_task]])[0]
model.components.defect_rate = new_defect_function
model.components.defect_rate()
0.0566754576475818
model.run().plot();